A comprehensive guide for fraud detection with machine learning
Check how machine learning has undergone a massive transformation to facilitate fraud detection.
Artificial Intelligence and Machine Learning
A comprehensive guide for fraud detection with machine learning
Check how machine learning has undergone a massive transformation to facilitate fraud detection.
Table of contents
Table of contents
Benefits of Fraud Detection via Machine Learning
How does Machine Learning Facilitate Credit Card Fraud Detection?
9 Common Fraud Scenarios – Application of Machine Learning Fraud Detection
Limitations of Using Machine Learning for Fraud Detection
Concluding Thoughts
The finance industry has undergone a massive transformation over the years, with the integration of technology. The most evident transformation has been in the way we look at payment transactions now. The digital payments market has seen a phenomenal growth in the last few years.
In 2020, the total value of digital payment transactions is projected at USD 4,934,741 million, reports Statista. The same report states that the number of users in Mobile POS Payments is expected to reach 1800.4 million by the year 2024.
With digital payments now having become the norm, more and more companies are vying for opportunities in this segment to ease out payments and make it more user-friendly & customer-centric. Some of the recent examples include:
A more recent addition has been WhatsApp Pay by WhatsApp
As digital payments have become commonplace, so have digital frauds. Fraud management has been painful for the banking and commerce industry. Fraudsters have become adept at finding loopholes. are phishing for naïve people and extracting money from them in creative ways.
As a result, companies have started to efficiently manage the vulnerabilities and close the loopholes within their payment systems through fraud detection via machine learning and predictive analytics. According to a study by VynZ Research, the fraud detection and prevention market is expected to reach USD 85.3 billion, growing at a CAGR of 17.8% during 2020-2025.
The main challenge for the companies attempting to full-proof their payment systems happen to be:
Acquiring excellent tools that can minimize payment risks and improve experiences
Getting skilled professionals who can help with fraud detection and innovate payment experiences.
Let us understand why machine learning is the most suitable method of fraud detection and how it can help organizations authenticate their payment systems.
First, let’s get a brief idea of machine learning.
What is Machine Learning?
Artificial Intelligence is the brainpower depicted by machines due to their ability to load and decipher the information offered to them. With AI, devices mimic humans. Machine Learning is a subset of AI. Computers learn from the data provided to them to perform the tasks assigned.
In machine learning, the computer builds training data using the information provided, which helps with predictions and decisions. As information is loaded to the machine, the data set improves, and the algorithm’s capability enhances, which can help in many ways, some of which are:
Sales Forecasting – The machines, based on the past sales date and the current sales transactions, can forecast the sales for the upcoming year. You will know which products will sell and how much quantity, thus helping with inventory management.
Personalization – Machine Learning details out your order history, your browsing behavior, as well as your demographics. It helps apps like Amazon & Netflix to arrive at recommendations that will enhance your app experience.
For fraud detection, machine learning ensures quicker resolutions and effective transactions.
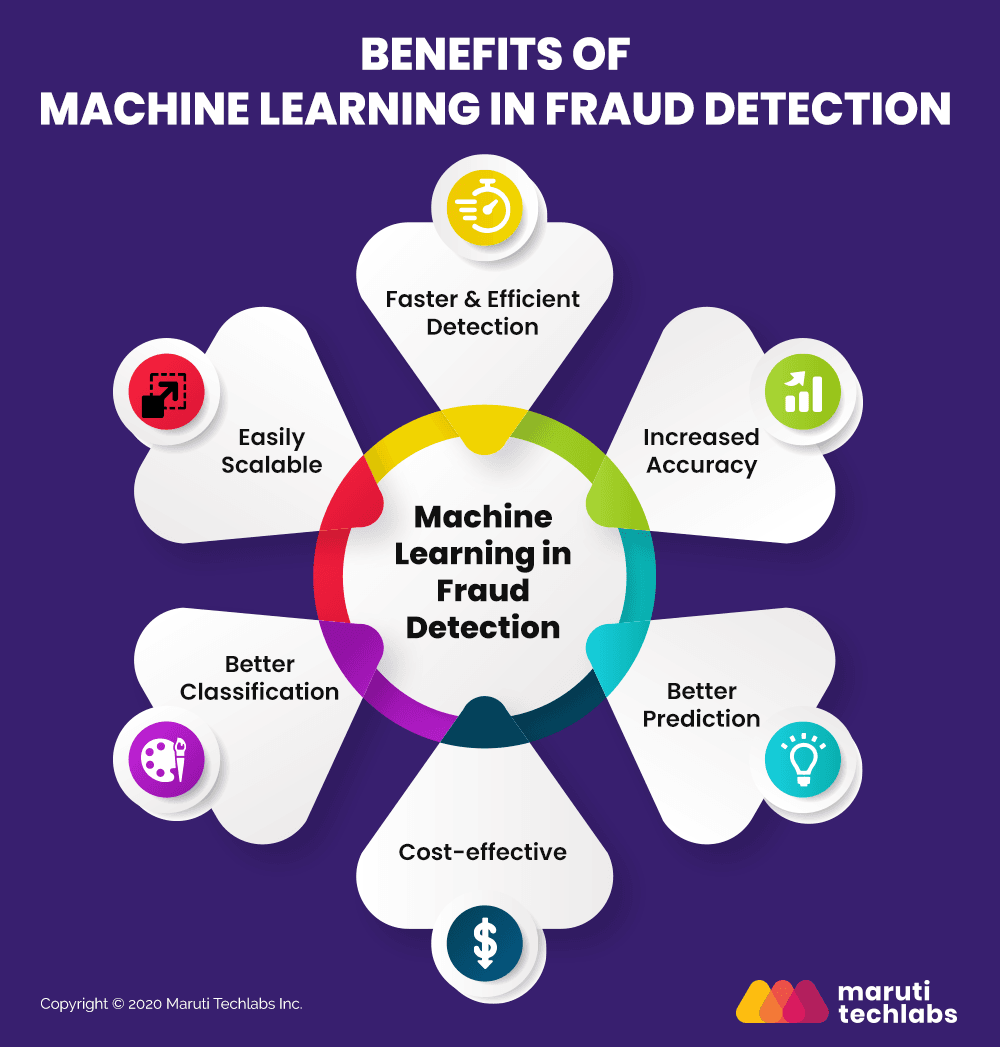
Benefits of Fraud Detection via Machine Learning
Machines are much better than humans at processing large datasets. They are able to detect and recognize thousands of patterns on a user’s purchasing journey instead of the few captured by creating rules.
We can predict fraud in a large volume of transactions by applying cognitive computing technologies to raw data. This is the reason why we use machine learning algorithms for preventing fraud for our clients.
Some of the benefits of fraud detection using machine learning are as follows –
Faster & Efficient Detection
Machine Learning offers an insight into how your user interacts with the apps. This includes an understanding of their app usage, payments, and even transaction methods.
As a result, the machine can quickly identify if the user has drifted from their regular app behavior. If there is a sudden spike in the amount that the user has shopped for from your site, it could be an anomaly. An approval from the user is needed for a go-ahead.
Machine Learning can quickly identify this anomaly in real-time, thus minimizing risk and securing the transaction.
Increased Accuracy
With Machine Learning, you can enable your analysts’ team to work faster and with greater accuracy. You are just giving them the power of data and insights, which means the time spent on manual analysis is reduced.
Let’s say your trained model has sufficient data. It would be able to differentiate between genuine and fraud customers. This would help ensure that your precision rate is high. As a result, fewer genuine customers would be blocked.
A customer has added a new card or a new payment method, which is not their ordinary course of behavior. Based on past data, the model can track the authenticity of the payment method as well as the customer’s records to understand if the transaction is fraudulent or not.
Better Prediction with Larger Datasets
Machine-learning improves with more data because the ML model can pick out the differences and similarities between multiple behaviors. Once told which transactions are genuine and which are fraudulent, the systems can work through them and begin to pick out those which fit either bucket.
These can also predict them in the future when dealing with fresh transactions. There is a risk in scaling at a fast pace. If there is an undetected fraud in the training data machine learning will train the system to ignore that type of fraud in the future.
Cost-effective Detection Technique
The fraud detection team had to handle the analysis and insight building of a large amount of data, which is time-consuming and tedious. The results may or may not be accurate, which would result in genuine customers being blocked at the payment gateways.
However, with Machine Learning at the core, your team will be less burdened and more efficient. The algorithms can analyze large datasets in milliseconds while offering data in real-time for better decision-making capabilities.
On the other hand, your core team can monitor and optimize the Machine Learning Fraud Detection algorithm to meet the end user’s requirements, thus improving the outcomes.
How does Machine Learning Facilitate Credit Card Fraud Detection?
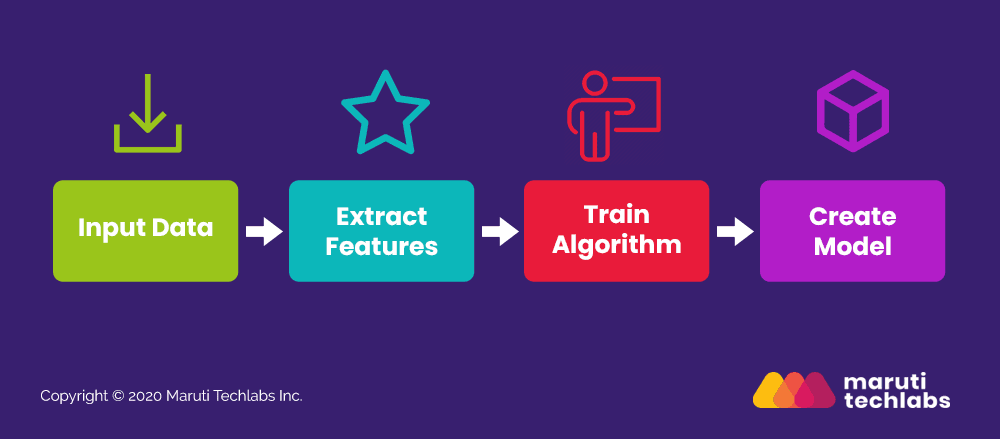
Fraud detection process using machine learning starts with gathering and segmenting the data. Then, the machine learning model is fed with training sets to predict the probability of fraud.
Let’s take a look at each of the elements in this process.
1. Input Data – There should be sufficient data available for Machine Learning to develop its algorithm.
There is too much noise available with the data you receive. The algorithm should be able to differentiate between good data, which consists of genuine customers and bad data, i.e., fraudsters.
When you segment this data, your model will be able to comprehend better and deliver results efficiently.
2. Extract Features – The features will help determine the signals that will help identify frauds.
The features important for fraud discoveries include:
Their network (emails, phone numbers, and payment details entered with the online account).
3. Train Algorithm – At this point, you will need to help the machine understand the difference between a fraudulent and a normal transaction. For this, you need to create an algorithm, train it using the learning data set, and help the machine make accurate predictions.
The features that you have added to the algorithm for fraud detection unsupervised learning along with the input data, will help train the machine towards better predictions.
4. Create Model – The training set will help the model understand and comprehend the algorithm defined. Once the training of the machine is over, you will get the exact model required for fraud detection.
The model will need to be improvised whenever new data or features are added to the system.
To help predict the models and ensure consistent results, different techniques are used to build models:
a. Logistic Regression
This technique uses a cause-effect relationship to devise structured data sets. Regression analysis tends to become more sophisticated when applied to fraud detection due to the number of variables and size of the data sets. It can provide value by assessing the predictive power of individual variables or combinations of variables as part of a larger fraud strategy.
In this technique, the authentic transactions are compared with the fraud ones to create an algorithm. This model (algorithm) will predict whether a new transaction is fraudulent or not. For very large merchants these models are specific to their customer base, but usually, general models will apply.
b. Decision Tree
This is a mature machine learning algorithm family used to automate the creation of rules for classification tasks. Decision Tree algorithms can be used for classification or regression predictive modeling problems. They are essentially a set of rules which are trained using examples of fraud that clients are facing.
The creation of a tree ignores irrelevant features and does not require extensive normalization of the data. A tree can be inspected and we can understand why a decision was made by following the list of rules triggered by a certain customer. The output of the machine learning algorithm might be a model like the following decision tree. This gives a probability score of fraud based on earlier scenarios.
c. Random Forest
Random Forest technique uses a combination of multiple decision trees to improve the performance of the classification or regression. It allows us to smooth the error which might exist in a single tree. It increases the overall performance and accuracy of the model while maintaining our ability to interpret the results and provide explainable scores to our users.
Random forest runtimes are quite fast, and they are able to deal with unbalanced and missing data. Random Forest weaknesses are that when used for regression they cannot predict beyond the range in the training data and that they may over-fit data sets that are particularly noisy. Of course, the best test of any algorithm is how well it works upon your own data set.
It is an excellent complement to other techniques and improves with exposure to data. The neural network is a part of cognitive computing technology where the machine mimics how the human brain works and how it observes patterns.
The neural networks are completely adaptive; able to learn from patterns of legitimate behavior. These can adapt to the change in the behavior of normal transactions and identify patterns of fraud transactions. The process of the neural networks is extremely fast and can make decisions in real time.
Choosing a Model for Real-time Credit Card Fraud Detection Using Machine Learning
The model that you choose should be able to identify these common anomalies in the system easily.
If there are multiple payment methods added from a single account within an hour, then it is a trigger that this account may be fraudulent.
If the customer is buying premium goods in large quantities, then your algorithm should be able to detect this fraud.
The location or the address added to the profile is fraudulent; i.e., it does not exist.
The email ID seems suspicious.
There is a mismatch in the account name as well as the name of the card.
Your training set should consist of data about these frauds. It is important to note that the model you choose also depends on your datasets as they work differently on datasets of different patterns.
9 Common Fraud Scenarios – Application of Machine Learning Fraud Detection
Let’s take a look at some of the fraud cases that exist in the real world and how ML can help detect them. You have likely experienced these frauds in one way or the other.
1. Email Phishing
In this technique, the fraudsters tend to con the recipients into answering the email with their data. Using the data, they can hack into your system and rob you of your money.
Machine Learning uses its algorithm to differentiate between actual and spam email addresses, thus preventing these frauds. They will read into the subject lines, the content of the email, as well as the sender’s email details before segmenting them into good or fraud email.
2. Identity Theft
This is another kind of fraud that needs to be brought to notice. In this case, the criminals tend to rob you of your identity connected with the bank accounts. They will change the IDs or the passwords, thus preventing entry into these accounts.
Machine Learning will ensure that nobody can change the password or update the identity associated with an account. As soon as anyone tries to hack into your account or plans to change the details, you will be notified. Two-factor security and other measures, along with human-like intelligence, help assure better prevention of frauds.
3. Credit Card Theft
Either through phishing or other methods, the fraudsters can get your credit card details and use it in systems that don’t need the physical presence of the cards. You will have to pay for the purchases you have not made.
Credit card fraud detection machine learning can prevent such compromises. The past purchases will tell a little about the customer’s buying behavior. It will also detail out the amount they are likely to spend, the kind of purchases they make, and the locations. If the purchase is abnormal, then the algorithm will detect and prevent fraud.
4. Document Forgery
Fakes IDs are available on the eCommerce market too, which can cause a lot of issues for the owner of these Ids. Machine Learning can ably identify the forged identity.
The algorithm has trained its neural network to differentiate between a fake and original identity, thus creating a full-proof system.
5. Formjacking Credit Card Details
It is the hijacking of your credit card details. While you are entering the details into a particular form online, the hacker would be ready with their tools to hijack the information and use it elsewhere.
This can be detected by the Machine Learning algorithm added to your website. It will secure the information and ensure that the data is not given to the attackers.
6. Fake Applications
If they have access to your IDs and other details, these fraudsters can use it to create a credit card. They will use the card while you will have to pay out the bills. The theft detection models have been devised for this specific reason, which accesses neural models to understand whether the application is real or fake.
7. Payment Fraud
The payment fraud includes lost credit cards, stolen cards as well as counterfeit cards. The fraudsters complete the payments while the owner of the cards has to pay these bills.
They are mainly used in transactions where the physical card is not essential and on vulnerable sites. There are separate detection models that identify the payment features and methods used in the past against the current technique.
8. Mimicking Buyer Behaviour
This is the new kind of fraud, where the criminal studies the buyer’s behavior and tries to imitate that. An in-depth understanding of the data can give Machine Learning the difference between the actual buyer and the fraudster.
Identifying the location spoofing details, knowing where the fraudster is making these purchases from, and other details need to be added to the ML algorithm for better & accurate results.
9. Advanced Software
Experienced hackers tend to use advanced anti-piracy and detection software, which can prevent regular browsers from recognizing them. They will create virtual IPs and machines, which allows them to commit the crime.
Machine Learning algorithms need to be fed with this data that can help them identify virtual IPs, machine anomaly, and fraudulent behavior. As a result, you can save the payment gateways from being crashed by frauds.
Limitations of Using Machine Learning for Fraud Detection
Machine Learning is a very useful technology that allows us to find patterns of an anomaly in everyday transactions. They are indeed superior to human review and rule-based methods, which were employed by earlier organizations.
But, as with any other technology, this technique of fraud detection has its own limitations:
1. Inspectability Issues
At Maruti Techlabs we maintain the backend machine learning model for our client. Thus we are required to explain the reasons for a buyer or seller being flagged as a fraudster and prevented from using the system. We also need to do this so that our client can confirm fraud and therefore train the system. In fact, machine learning is only as good as the human data scientists behind it.
Even the most advanced technology cannot replace the expertise and judgment it takes to effectively filter and process data and evaluate the meaning of the risk score. So while we have eliminated this problem through rule-based techniques, lack of inspectability can be a drawback of certain other machine learning-based approaches.
2. Cold Start
It takes a significant amount of data for machine learning models to become accurate. For large organizations, this data volume is not an issue but for others, there must be enough data points to identify legitimate cause and effect relationships.
Without the appropriate data, the machines may learn the wrong inferences and make erroneous or irrelevant fraud assessments. It’s often better to apply a basic set of rules initially and allow the machine learning models to ‘warm up’ with more data. We often apply this approach with smaller datasets.
3. Blind to Data Connections
Machine learning models work on actions, behavior, and activity. Initially, when the dataset is small, they are blind to connections in data. The model can overlook a seemingly obvious connection such as a shared card between two accounts. To counter this we enhance our models with Graph networks.
Graph technique can find multiple bogus actors for every single one prevented through scoring. Graph databases allow us to block suspect and bogus accounts before they have taken any fraudulent action. Following image shows a simple buyer insurance fraud case represented as a graph.
Concluding Thoughts
To detect suspicious activity, and more importantly to separate false alarms from true fraud, PayPal uses a homegrown AI engine built with open-source tools. As a result of this human and AI solution, Paypal has decreased its false alarm rate to half.
Machine learning techniques are obviously more reliable than human review and transaction rules. The machine learning solutions are efficient, scalable and process a large number of transactions in real time.
Maruti Techlabs is focused on improving customer experiences through technology. Having worked on challenging projects from around the world, we understand how to navigate through strict regulations and risk of replacing existing technology when it comes to automation.
Our machine learning experts enable rapid decision making, increased productivity, business process automation, and faster anomaly detection through a myriad of techniques. To get on a call with our artificial intelligence experts, drop us a note here.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!