What is Elasticsearch? What it is Used for? Working, Benefits
Understand the importance of elastic search and how it can help uplift your business.
Data Analytics and Business Intelligence
What is Elasticsearch? What it is Used for? Working, Benefits
Understand the importance of elastic search and how it can help uplift your business.
Table of contents
Table of contents
Why Elasticsearch?
What is Elasticsearch?
How Does Elasticsearch Work?
Basic Concepts Of Elasticsearch
What Is Elasticsearch Used For?
Benefits Of Using Elasticsearch
FAQs
What is Elasticsearch, you ask? Elasticsearch is a distributed document-oriented search engine, designed to store, retrieve, and manage structured, semi-structured, unstructured, textual, numerical, and geospatial data.
Huh?
For a better understanding, let’s take a look at the basics first.
For your business to provide superior customer service, your customers need to be able to search quickly for their preferred product/service from your enormous product base. For your organization to run effectively, you need to be able to access data and analytics from your enormous database seamlessly. Easy handling of data and serving information faster form the backbone of an efficient and successful organization.
Your investment in efficient data engineering solutions is the only underlying prerequisite to achieving this feat.
Delay in retrieving information leads to poor customer service and you might end up losing a potential customer. This lag in search is attributed to the relational database used for the product design, where the data is scattered among multiple tables, and retrieval of meaningful user information requires fetching the data from them.
Elasticsearch, a powerful search and analytics engine, is frequently leveraged by analytics service providers to efficiently index, search, and analyze vast volumes of data for their clients' needs.
Why Elasticsearch?
Relational Database works comparatively slow when it comes to huge data sets, leading to slower fetching of search results through queries from the database. Of course, RDBMS can be optimized but that also brings with it a set of limitations like, every field cannot be indexed, and updating rows to heavily indexed tables is a lengthy and excruciating process.
Businesses nowadays are looking for alternate ways where the data is stored in a manner that the retrieval is quick. This can be achieved by adopting NoSQL rather than RDBMS for storing data. Elasticsearch is one such NoSQL distributed database. Elasticsearch relies on flexible data models to build and update visitors’ profiles to meet the demanding workload and low latency required for real-time engagement.
What is Elasticsearch?
Let’s understand what makes Elasticsearch the obvious choice. Elasticsearch (ES) is a document-oriented search engine, designed to store, retrieve and manage document-oriented, structured, unstructured, and semi-structured data. Elasticsearch uses Lucene StandardAnalyzer for indexing for automatic type guessing and more precision. When you use Elasticsearch you store data in JSON document form. Then you query them for retrieval. It is schema-less, using some defaults to index the data unless you provide mapping as per your need.
Every feature of Elasticsearch is exposed as a REST API:
Index API – Used to document the Index
Get API – Used to retrieve the document
Search API – Used to submit your query and get the result
Put Mapping API – Used to override default choices and define our own mapping
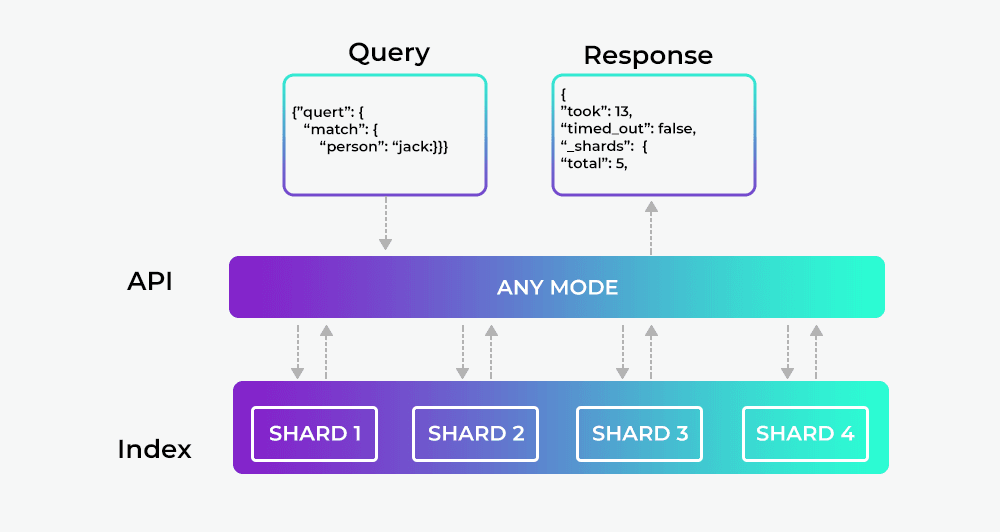
Elasticsearch has its own Query Domain Specific Language, where you specify the query in JSON format. Other queries can also be nested based on your need. Real projects require search on different fields by applying some conditions, different weights, recent documents, values of some predefined fields, and so on. All such complexity can be expressed through a single query. The query DSL is powerful and designed to handle the real world query complexity through a single query. Elasticsearch APIs are directly related to Lucene. Query DSL also uses the Lucene TermQuery to execute it.
The below figure shows how the Elasticsearch query works.
How Does Elasticsearch Work?
Elasticsearch is known for its ability to offer quick results and analytical capabilities. It does this by storing data indexed data in the form of documents and facilitating a full-text search. Let’s observe the workings of Elasticsearch in brief.
It stores data as JSON documents within the fields in each document.
Elasticsearch breaks down texts into tokens i.e. individual words, storing them as inverted index when indexing a document. The inverted index can be considered a reference table that enables fast searches by maps each word to the document.
When a query is entered, it calculates the relevance score for each document and return relevant results.
Being a distributed system, data is stored in clusters across multiple nodes. Each node participates in indexing and searching queries by storing a subset of the data.
The data is divided in cluster across nodes using a technique called ‘Sharding’. Each node can store multiple shards, with each shard being a subser of the data. This facilitates horizontal scaling adding numerous nodes to the cluster.
Elasticsearch also enhances redundancy and availability to mitigate the risks of node failure. It does this by supporting replication (offering one or more copies of each shard).
The search engine is compatible with tools like Kibana for visualization and Logstash for data ingestion. It also offers a robust search API to conduct complex search queries, aggregations, and analytics.
Now that you’re aware of how Elasticsearch works, let’s learn what it can best be used for.
Basic Concepts Of Elasticsearch
Let us have a look at the important concepts of Elasticsearch:
Cluster: A cluster is a collection of one or more servers that together hold entire data. It gives federated indexing and search capabilities across all the servers. For Relational Database, the node is a DB instance. There can be N nodes with the same cluster name.
NRT (Near Real-Time): Elasticsearch is a near real-time search platform. There is a slight from the time you index a document until the time it becomes searchable.
Index: Index is a collection of documents that have similar characteristics. For example, we can have an index for customer data and another one for product information.
An index is identified by a unique name that refers to the index when performing indexing search, updates, and deletes operations. In a single cluster, we can define as many indexes as we want.
Index = Database Schema in RDBMS (Relational Database Management system). Similar to a database, or schema. Consider it a set of tables with some logical grouping.
In Elasticsearch terms, Index = Database, Type = Table, Document = Row.
Node: A single server that holds some data and participates on the cluster’s indexing and querying is called node. A node can be configured to join a specific cluster by the particular cluster name.
A single cluster can have as many nodes as we want. A node is simply one Elasticsearch instance. Consider this a running instance of MySQL. There is one MySQL instance running per machine on a different port. While in Elasticsearch generally, one Elasticsearch instance runs per machine. Elasticsearch uses distributed computing so having separate machines would help as there would be more hardware resources.
Shards: Shard is a subset of Documents of an Index. An index can be divided into many shards, or to put it in a different way, an index is a group of shards.
ElasticSearch uses document definitions that act as tables. If you PUT (“Index”) a document in ElasticSearch, you will notice that it automatically tries to determine the property types. This is like inserting a JSON blob in MySQL, and MySQL determining the number of columns and column types, as it creates the Database table.
What Is Elasticsearch Used For?
So far, we have understood the answer to the question: ‘what is Elasticsearch?’ and the basic concepts associated with Elasticsearch. But it is equally important to know when to use Elasticsearch. Let us have a look at what Elasticsearch is used for.
Textual Search (searching for pure text) – Elasticsearch is primarily used where there is lots of text and we want to search any data for the best match with a specific phrase.
Product Search – Elasticsearch is used to facilitate faster product search using properties and name (textual search and structured data).
Data Aggregation – The aggregation’s framework helps provide aggregated data based on a search query. It is based on simple building blocks called aggregations, that can be composed in order to build complex summaries of the data. An aggregation can be seen as a unit-of-work that builds analytic information over a set of documents. The context of the execution defines what this document set is (e.g. a top-level aggregation executes within the context of the executed query/filters of the search request).
JSON Document Storage – A JSON object with some data. It’s the basic information unit in ES. The document is a basic information unit that can be indexed.
Geo-Search – Elasticsearch can be used to geo-localized any product. For example, the search query: ‘all the restaurants that serve pizza within 30 minutes’ can use Elasticsearch to display information of the relevant pizzerias instantly.
Auto-Suggest – It allows the user to start typing a few characters and receive a list of suggested queries as they type.
Auto-Complete – Elasticsearch database helps in autocompleting the search query by completing a search box on partially-typed words, based on the previous searches.
Metrics & Analytics – Elasticsearch analyzes a ton of dashboards consisting of several emails, logs, databases, and syslogs, to help businesses make sense of their data and provide actionable insights.
Elasticsearch users have delightfully diverse use cases, ranging from appending tiny log-line documents to indexing web-scale collections of large documents and maximizing indexing throughput is often a common and important goal.
Benefits Of Using Elasticsearch
The growing popularity of Elasticsearch within small and huge corporations alike testifies the huge number of benefits it brings to the table. Let us have a look at some of the key benefits of using Elasticsearch
Direct, Easy, and Fast access: Documents are stored in close proximity to the corresponding metadata in the index. This reduces the number of data reads and as a result increases the search result response.
Manages huge amounts of data: As a comparison to the traditional SQL database management systems that take more than 10 seconds to fetch required search query data, Elasticsearch can do that within a few microseconds (10, to be exact).
Scalability of the search engine: As Elasticsearch has a distributed architecture it enables us to scale up to thousands of servers and accommodate petabytes of data. The customers then need not manage the complexity of distributed design as it has been done automatically.
Sometimes we have more than one way to index some documents or query them and with the help of Elasticsearch, we can do it better. Elasticsearch is not new but it’s evolving rapidly, new features are getting added. But the core is consistent and can help achieve faster performance with search results for your search engine.
To manage and scale your Elasticsearch environment and make the most out of it for your business, simply drop us a note here and our experts at Maruti Techlabs will get in touch with you.
FAQs
1. How do you pull data from Elasticsearch?
To perform a search, try options such as ‘Search Application’ or ‘Search API’. Elasticsearch uses a search query named ‘Query DSL’ and enables data searching and aggregation.
2. What is a type in Elasticsearch?
This is a form of indexing that quickens the searching process by using the ‘type’ name. It can be accessed when using scripts, queries, aggregations, and sorting.
3. How do I know if Elasticsearch is working?
Try running a command curl localhost:9200 in your terminal. If Elasticsearch has been activated, you will receive a JSON response with information about your Elasticsearch Cluster.
4. How does Elasticsearch differ from traditional databases?
Traditional databases offer consistency and structured data management. However, Elasticsearch provides precise search and analysis of unstructured data with unparalleled speed, accuracy, and scalability.
5. What are the core components of Elasticsearch?
Analyzers, clusters, shards, and nodes are the core components of Elasticsearch.
6. How does Elasticsearch handle unstructured data?
Elasticsearch indexes the data using an inverted index to handle unstructured data, facilitating quick searches. It enhances searchability and querying capabilities across vast data sets using analyzers and tokenizers to process data.
7. In what industries is Elasticsearch commonly used?
Elasticsearch can be used by industries like eCommerce, Healthcare, Finance, Technology, and Media for log and event data analysis, business intelligence, real-time analytics, and search engines.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!